Welcome to the second post of our Founder’s Series! You can find our first post in https://nuvalab.ai/2023/11/19/journey.html where we wrote about our early exploration of “AI Town”, what works, what doesn’t work from hands on experiments from March to May, 2023, prototype v1 and v2. These are valuable corner stones that sets the path to where we’re right now, despite being very early.
In this blog post, you will see:
- Quick recap from prototype v1, v2
- Design principles of v3, v4
- What’s different in v3, v4
- Demo videos
- Highlights and lowlights from real user feedbacks
- Recap and key takeaways that leads to our alpha mobile product
- What’s next
This blog is a continuation of the series that covers our exploration from June to Oct, 2023, prototype v3 and v4.
Please keep in mind that our latest version of mobile product looks completely different from what I wrote in this post post, as this version mainly focuses on exploring and pushing the limitations of AI Agents, despite they use exactly the same backend multi-agent framework we built in-house.
Quick recap from prototype v1, v2
In our early explorations, we found that there’re indeed sparkles of fun that could happen, but at extremely low probability that’s infeasible for a user facing product. Also, consistency and controllability are key issues that needs to be addressed.
Another key observation is people love to feel in control and influence over an experience, and in the most time, pure simulations does not provide that, despite carefully designed simulation can help as an effective mechanism of progression where user is not paying attention.
Design principles of v3 & v4
Among the four key verbs of user action: Play, Create, Watch and Share — this version heavily focuses on “Play” while previous ones focus more on “Watch”. Essentially we hand over the steering wheel to the user as the center of this experience, to a degree that I will refer to the user as “Player” for this version.
We built it with a stronger structure and goal setting, which are essential as we learned from simulation AI Town. It even has three main stages: phone unlock (casual puzzle), convince the saloon owner (LLM chat, action and reasoning) and finale (storytelling). Each stage has an objective for the player with varying depth and difficulty.
As part of our core vision, we continued on the path of autonomous and collaborative multi-agents. In addition to the AI Town version, players are able to directly talk to the agents and influence their behaviors with real-time response.
It’s a pure vertical experience to push the limit of AI Agents, essentially “build things in the none scalable way”, a luxury for small teams :)
What’s different in v4
Strong and rigid “structure” of the experience. As our v1 and v2 mentioned, all good experiences need thoughtful UX design, specially AI native ones that seems to always offer “infinity” right off the bat. In this version, we acknowledged the importance of agent controllability in order to make meaningful progress, thus introduced a “Dungeon Master” agent in the backstage. It oversees entire game state, dynamically change and dispatch objective to all agents as if the director of a show, or “master” node of a cluster in distributed computing.
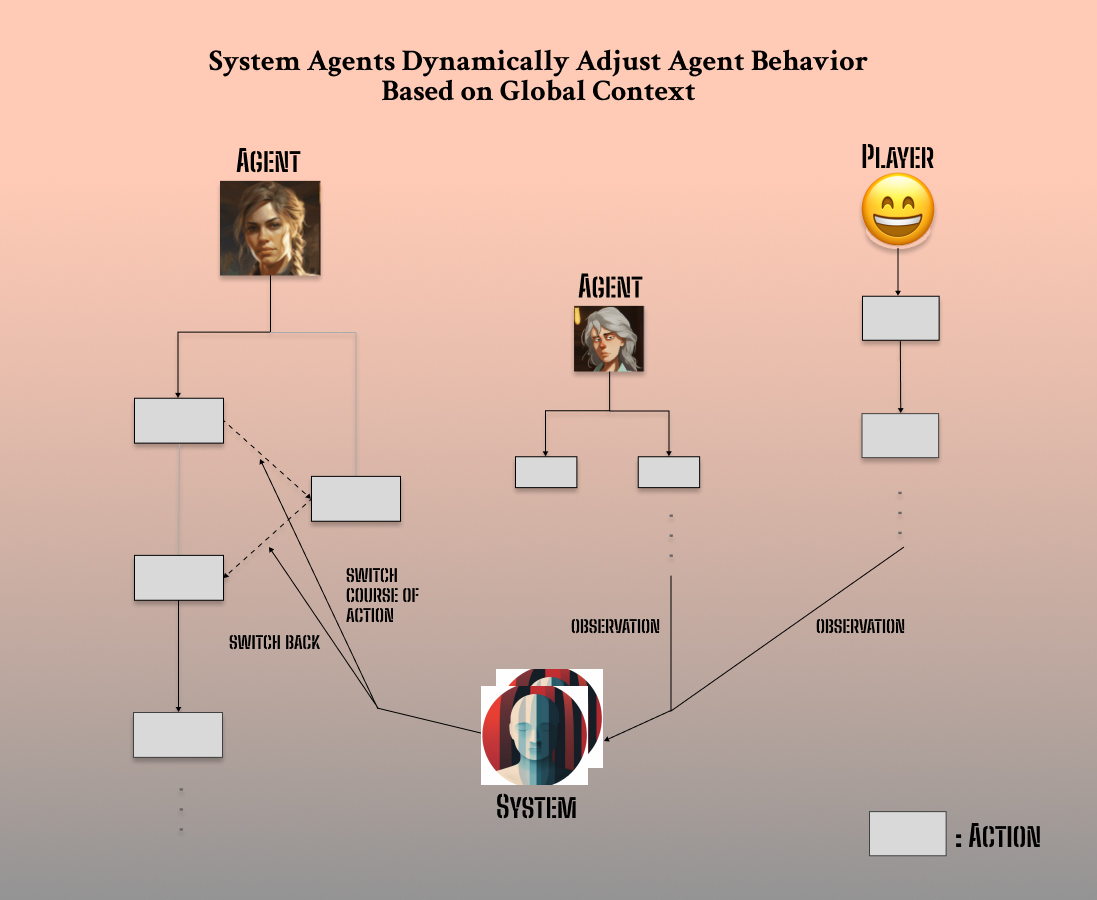 (DM Agent that dynamically dispatches objectives and tasks)
(DM Agent that dynamically dispatches objectives and tasks)
Complete different tech stack, on purpose. In order to maximize learning from this attempt, we deliberately changed EVERYTHING full stack:
Frontend: Three.js → Unity
- This is a bold move to explore the frontier of real gaming development stack. With real 3D agent with path finding, rigging and animations. We even brought a few packs from Synty Studio just to have a sense of how scalable would it be to scale 3D characters and scenes.
Backend: Built in-house multi-agent framework from scratch
- With experience accumulated from town prototype, we get much more clarity on the agent abstraction we need. Since existing ones didn’t satisfy our needs, we wrote one on our own: message passing, event handling & observation, memory & compaction, dialog, action modules, etc.
LLM: In-house serving → OpenAI endpoint
- Using endpoint helps to accelerator our development speed. Also since using OSS model won’t bring us new signals, it’s helpful to deliberately try out best commercial LLM available, to see what the “upper limit” looks like. It turned out to be one of the best decision made.
Added “Action” and “Decision Making” dimension of the agent. That’s the meat of agent we believe in — we want to give agents “arms and legs” so they can do stuff with you. This is where emergent behavior and fun happens. You can see we’ve been very skeptical about chatbot as the primary format of media & entertainment, and all attempts are pushing its boundary to seek “what’s next”.
Demo Videos
(Prototype v3)
This is a silly early version of it. Agents are primarily just … ranting but still able to make progress under some loose constraints. It’s an important milestone however, since that’s the first time that we 1) observed multi-agent engagement with persona 2) user is able to broadcast messages to all other agent’s memory 3) enabled real-time text to speech, which turn out to make a big difference be immersive — you might not think like Elon, but you can certainly sound like him!
(Prototype v4, Act 1, casual puzzle)
In this scene, player is paired with her “inner voice” to guide her to unlock her cellphone, then she can make a phone call to bring in an agent of her choice for Act II.
(Prototype v4, Act 2, controllable multi-agent)
In this scene, player needs to work with the called in agent, navigate the situation by having conversation with saloon owner and bartender, examine objects in the saloon, and ultimately — sneak into the backroom by convincing the saloon owner, Bella, to move away from her current position. (Eastern egg: The bartender, started as female under name Rica, is actually Rick from “Rick and Morty” who got stuck time traveling to 1860s. Correctly identifying his true identity changes the ending.)
This is where all the meat is. Sooooo many things are happening behind this scene, to a degree that we got to admit we likely even went too far at the cost of generalization, but all the signals we got are worth the effort. Not to mention battle testing and building our multi-agent framework with a real and complicated use case.
(polished trailer with less meat in it)
This is a TL;DR for common audience who might not care as much about the technical stuff underneath :)
Highlights and lowlights from real user feedbacks
We got ~500 test users in two weeks by just putting it out there without advertising. Plus a few in-depth zoom user interviews.
Highlights:
- Compare to the town prototype, it’s a lot more immersive and actually usable by the end user. We can call them “player” and see their engagement with the experience last beyond 1hr session, as the result of our user-centric design from simulation.
- It’s very interesting that the most loved scene is Act I - phone unlocking, despite we put the least amount of development time into it.
- I think people loved its simplicity and well-contained scope: clear and simple goal, no distraction, no confusion, instant feedback loop. Multiple users explicitly told me: “Can you just make infinite levels of this plus a leaderboard”
- This suggest we need to double down on “flat” experiences with very clear, simple objective and extremely short feedback loop.
- Demonstration of LLM’s capabilities got a lot of people excited.
- A friend of mine working on applied machine learning and heavy gamer messaged me “Hey you guys should totally try to sell this to RockStar for GTA6”.
- Talking to real users from offline demo event felt very encouraging :)
- We touched multiple boundaries of AI Agent with GPT-4, specially on reasoning and action.
- Some concrete examples include GPT-4 can often fail to answer “is 2008 higher than 2004” or “Did anyone mentioned facts or terms that suggest she is a time traveler”.
- And obviously, we gained a lot of first-hand experience on Agent’s true ability (or should I call it “unknown limitation” instead) on planning and emergent behavior.
Lowlights:
- Expectation management. People compared us with AAA grade game.
- The key to building new experience is to find the sweet spot to make it 10x better. Therefore when people unintentionally comparing this game to GTA from RockStar or ask me “Do you guys want to be AI MiHoyo” — this means we’re off at product positioning. Existing games are heavily industrialized with extremely high bar.
- Infinite possible inputs with unstable feedback
- This is the same issue from town demo, but manifested in slightly different way. Multiple people handed off the laptop back to me saying “I’m not that creative, can I just watch you play” defeats the purpose of this prototype as consumer facing. Majority of common people don’t know what to say to an empty input box.
- What makes it even worse is, due to instability of LLM responses, users still suffer big churn of response quality not meeting their expectation. There’s no clear calibration or instant progression check for AI native experiences. People simply don’t know what to expect, and easily get disappointed, or do not know how to interpret responses from LLM. “Why is Bella not moving when I told her? Did I say something wrong, or maybe just AI is dumb?”
These points touched on the art of experience design, managing expectation and dance within known & unknown limits of LLM.
- Mapping LLM to limited physical interaction space still goes through a “narrow waist”
- This is about the “action” dimension. People often say asset is easy, rigging is hard. For AI native experience, regardless of how wild the user input is, we always need to map them into a discrete subset of pre-defined actions, such as “WALK TO”, “SPEAK”, “SHOOT” .. you name it. This brings limitation to agent’s ability to act, and most importantly, generalize. Agents can play Minecraft with GPT-4 because GPT-4 has context of Minecraft. But no LLM can reliably be proficient on tasks within context domain it has never seen, or maybe not even able to see.
- As a result, this leads to scalability issue that defeats the purpose of AI UGC. Despite that’s not the intention of our prototype when it’s established, it’s very clear these limitations capped creator supply and experience verticals that can be created with this AI Agent native approach.
Recap and key takeaways that leads to our alpha product
People are not as creative as we think, and will have trouble setting expectations right, or be well calibrated to evaluate AI responses. So we need to make things extremely simple and intuitive, to lower the cognitive burden on end users.
Stories are about people, not puzzles, or things. It took us a while to nail the punchline as “AI Interactive Story” for a reason. For people who are a bit more familiar with novels, characters are the core pillar of stories, but stories are not about puzzle or objects, which are presented too heavily in this prototype.
Extremely simple things can scale way better, as demonstrated earlier on narrow waist, objective setting and current LLM’s ability boundary to reason with given context.
With these learnings, we’re well equipped to iterate on the next version, which is mobile first. Mobile app by design has to be much simpler in format, with short session time such that it can be done on Lyft ride.
What’s next
In the next post, I will write about our alpha mobile product, following similar structure of our blog post series so far — design principle, highlights & lowlights and key take aways. Spoiler alert — this is still not our formal product yet, but it’s getting really close. The best one is always the next one :)
Again, please join our Discord to influence our roadmap and follow our threads to keep up with latest changes!